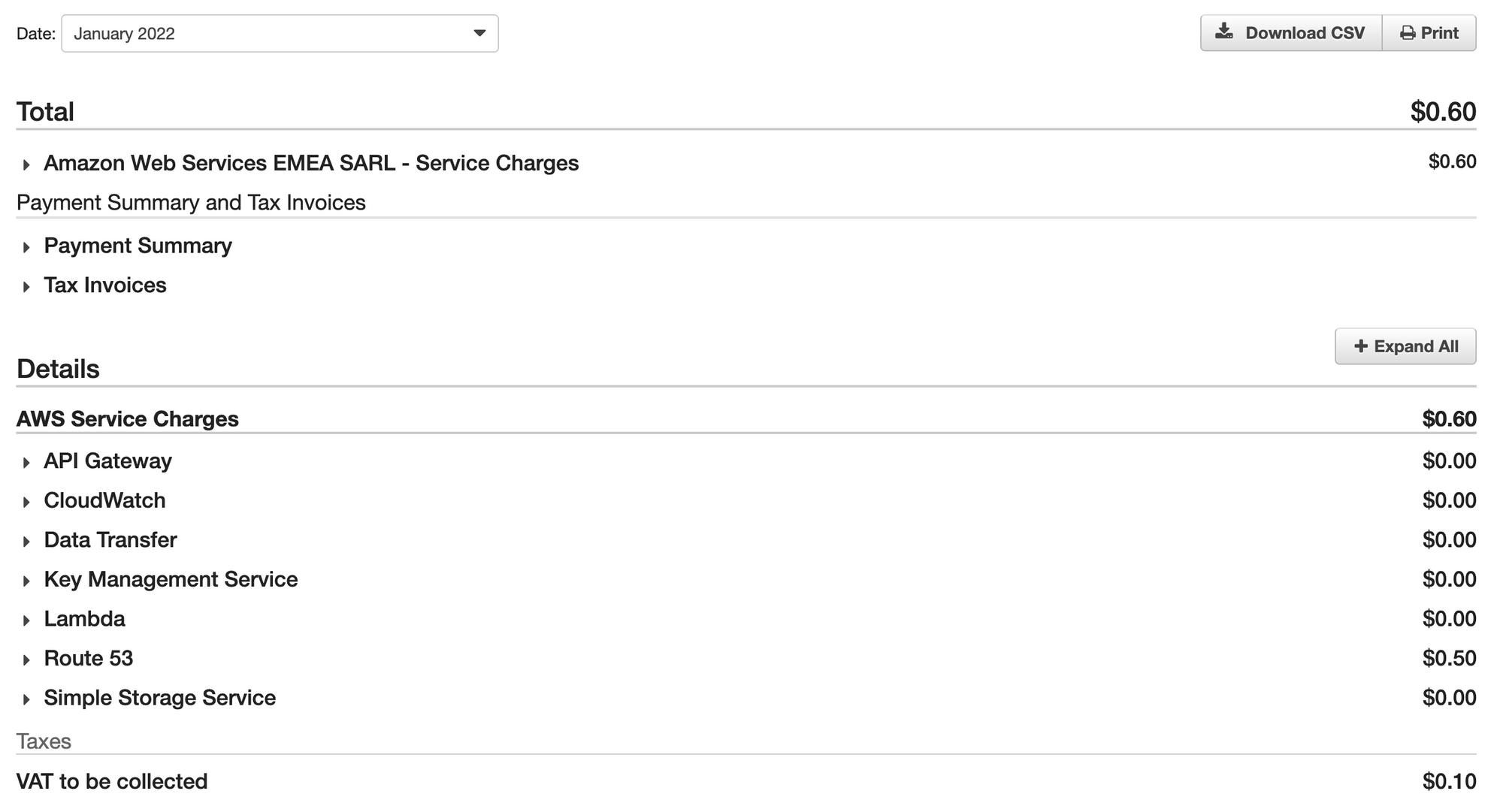
GDPR compliance for 0.5 USD per month. Plus VAT.
The art and science of using modern cloud technologies to solve boring business problems at virtually no cost.

Last year I was approached by a local property brokerage and development company with a problem — they had tens of thousands of contacts in their CRM, but unable to contact them without violating GDPR regulation.
The company ain't no spring chicken, most of their contacts had been in the database for years, added long before GDPR was "a thing". The company wasn't doing anything illegal, none of the contacts in the database had been added without their consent. Quite the opposite. The contacts in the CRM database — the people interested in buying property — had been added at their request. Ditto for any new contact added to the CRM database.
And there lies the crux of the problem. The CRM is an essential tool for the company staff. It's where work happens. But there is no digital record of the company requesting the prospective buyer to opt into receiving offers. And no way to record the opt-in consent in the CRM. Not easily, anyway.
There had been a few instances where a recipient of an offer shot back a semi-angry email asking to see proof that they had opted into the company's offers as a prospective buyer. With stories of lengthy legal battles and exorbitant fines around GDPR, the company leadership was eager to solve the problem once and for all.
Initial steps
The first couple of meetings with the client revealed several nuances around the details. What do we do about old buyers in the CRM database? Under what conditions should the opt-in email be sent? How and where do we record the information about the contact having received an opt-in email and having consented (or not) to receiving offer emails from the company?
The initial approach we explored was figuring out whether or not it's possible to do this with the CRM's built-in functionality. Scoro seems pretty powerful, but it didn't look like it was possible to craft a custom e-mail template with an "Opt in" button and hook that up so that some custom field gets filled automatically when the recipient clicks on the button. I'm surprised that the opt-in flow is not taken care of by the CRM software.
So, unfortunately, the CRM-native e-mail flow proved to be a dead-end. Upon reflection, I think this would've been a fairly naive implementation of what we were trying to do — we wanted to handle the contact's roles changing as well, for example.
Second attempt
Back at the drawing board, we realised that we'd probably have to build a custom piece of software to handle the entire opt-in flow. It would take care of sending the opt-in e-mail, handling the contact opt-in form, listening for contact role changes (from Seller to Buyer, for instance), and syncing information to Scoro to be seen and filtered on by the company's brokers.
The initial dead-end approach did have a silver lining — it revealed the ability to attach custom fields to each contact. We could use custom fields to record information from outside the system — like the custom opt-in widget! Luckily, the Scoro API exposes custom fields and allows the API client to interact with them almost as transparently as any other field. I went to work devising a system that could listen for new and updated contact events, send opt-in e-mail according to agreed-upon logic, present a form with opt-in fields, and synchronise data to and from Scoro.
The solution
One of the things the client prioritised was ongoing cost. They didn't want to pay a ton of money every month for keeping the widget going. This aligned quite nicely with my technical goals for this project, which I wanted to keep as simple as possible. To that end, I wanted to rely on as few external components as possible. I didn't want to use a database, either. I didn't want to keep any state outside Scoro whatsoever. I ended up devising a system built on a couple of custom fields in Scoro:
- a custom field for storing the actual opt-in for receiving offers;
- a custom field for storing the opt-in for receiving the company's newsletter (not shown in the below screenshot); and
- a custom field for storing the.. err.. database, which is just a JWT that encodes the contact's ID and their roles — are they a buyer, a seller, an old client, etc.
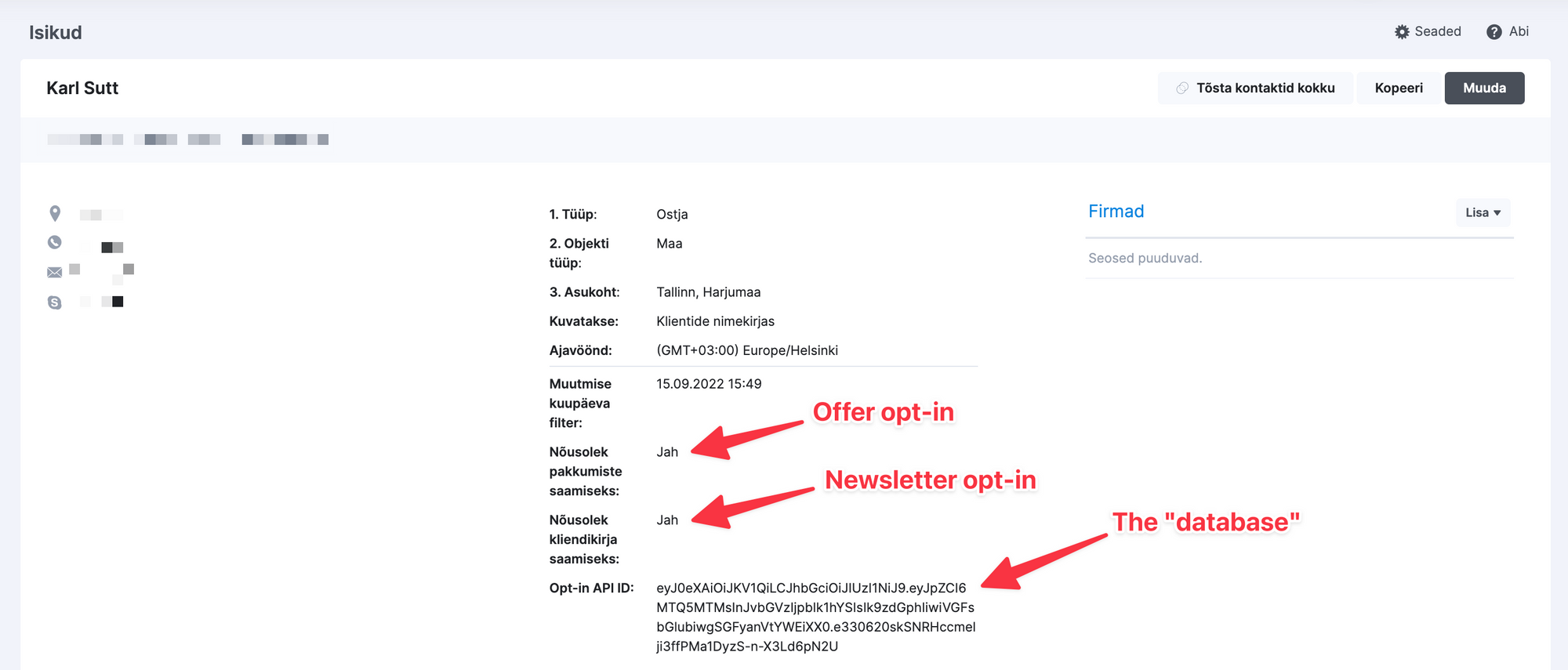
The database.. I mean the JWT is used to keep a minimum amount of state to be used by the external opt-in software. It needs to know how, if at all, the contact's roles change. Every time a contact is updated in Scoro the opt-in widget receives a webhook. Sadly, the webhook doesn't contain any information about what changed, only the new version of the entity. Since the JWT stores the contact's roles, it acts as a tiny bit of short-term memory allowing the widget to work out how the contact's roles changed and if it needs to send the opt-in e-mail.
Technology
Being a self-appointed member of the Boring Technology Club I chose Python and Flask as the core of the system. I've worked with both for years and know them inside out. Other boring technology used includes Pydantic for data (de-)serialisation, Flask-Mailman for sending e-mail through the company's SMTP servers, Flask-WTF for form handling and Tailwind CSS for making the form look pretty.
I initially deployed the app to render.com for testing with real data and presenting to the client for feedback. At the time, Render didn't have a free tier. The cheapest plan was $7/mo. The widget was just sitting there doing nothing most of the time, it seemed wasteful paying that. And of course, the client was interested in keeping the costs low. You could argue that $7/mo isn't the most expensive thing in the world, but paying $7/mo for doing essentially nothing is quite expensive.
We had just started talking about serverless at $WORK and even though I am sceptical of the benefits for large complex applications, it seemed like a great opportunity to learn more about the technology. I hadn't used any innovation tokens on building the app itself, so I felt that paying one or two tokens for exploring serverless could be a pretty good bet. The extremely competitive per-ms pricing coupled with the reduced stress of not having to manage servers made serverless seem like a great fit for this project.

The first course of action was to explore Chalice as a potential vehicle for deploying the opt-in widget as a serverless stack. Given that the Chalice Github project lives under the AWS Github account, it seemed like the way to go — an official AWS-approved way to deploy an app to AWS Lambda. But soon after diving in I realised I'd have to re-build most of the app I'd already built in Flask, in Chalice. Bummer.
A bit of Googling surfaced another library/framework called Zappa. The README immediately looked promising:
Zappa makes it super easy to build and deploy server-less, event-driven Python applications (including, but not limited to, WSGI web apps) on AWS Lambda + API Gateway. Think of it as "serverless" web hosting for your Python apps.
[...]
It's great for deploying serverless microservices with frameworks like Flask and Bottle, and for hosting larger web apps and CMSes with Django. Or, you can use any WSGI-compatible app you like!

The setup was very quick indeed — I created a zappa_settings.json file with the appropriate AWS resource ARNs, ran zappa deploy production and sure enough, the moments-ago-boring WSGI app was now a fancy server-less wonder deployed on AWS Lambda and API Gateway. Pretty cool!
I spent a couple more hours getting the subdomain for the widget set up correctly with Route 53 and ACM, and wiring that up to the API Gateway custom domain configuration.
The payoff
To put it all into perspective, the EU data protection authorities can impose fines of up to 4% of annual turnover in very severe cases. The worst case scenario for the client would be getting fined north of a hundred thousand euros. It's unlikely that it would ever come to that, but the risk is still there.
GDPR is a good thing in general, but I think it's much easier for larger companies to deal with it than it is for smaller companies. The regulation does not differentiate based on company size. A Google-sized company can throw millions of euros behind getting it right (and still get it wrong). What hope is there for small companies who have to be as compliant as Google on the face of it, but have microscopic budgets compared to Google?
But.. the innovation tokens paid off! At the current traffic levels and with a whole lot of headroom, the client is paying $0.5 per month + VAT — that's ~12x cheaper than the initial spike with Render. Not bad for avoiding tens, if not hundreds of thousands of euros in fines.
(Edit: As David Chisnall pointed out on lobste.rs — the described solution is incomplete. And I agree. The opt-out / right-to-be-forgotten flow isn't very polished at the moment. We're still working on that.)